Week 5 Prep: Decision Trees & Project 2 Intro
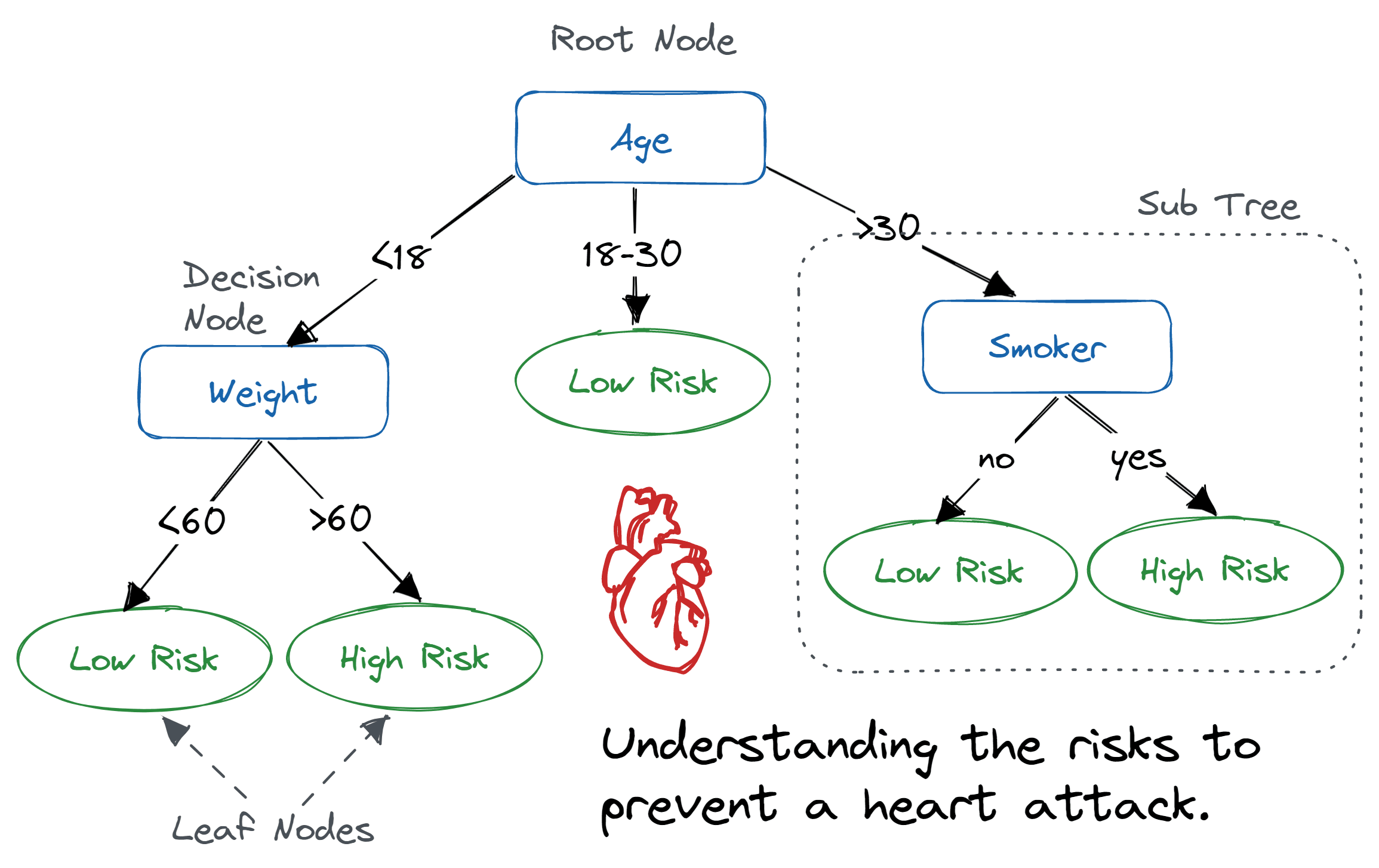
Decision Tree Structure
Decision trees are structured like a flowchart and have the following components:
- Root Node: the starting point that represents the entire dataset (the main node)
- Branches: from the root, branches of questions or test conditions. Based on the answer, the branch is followed to one or another. Each branch represents the outcome of the question (for example, true or false)
- Internal Nodes: additional decision points further down the tree where more questions are asked. Each internal node splits the data based on a specific feature or condition
- Leaf Nodes: these represent the final outcomes or decisions. In a classification tree, a leaf might label the data as belonging to a specific category (like spam vs not spam), or in a regression tree, it might provide a numerical prediction.
Decision Tree Function
A decision tree works in the following way:
- Ask a question: at each node, the tree asks a question about one of the features in the data. For example “is the weather sunny?”
- Split the data: based on the answer (true/false), the data is divided into groups. This process is repeated at each node.
- Reach a decision: when you arrive at a leaf node, the tree provides the final decision or classification.
Decision Tree Example
Project 2 Introduction
Using this Car Price dataset, I would like to be able to classify the car into its respective brand based on parameters such as price, year, engine & transmission parameters, and mileage. The goal of this project will be to see if it is possible to determine a vehicle’s brand based on such parameters.
The potential impact is that the model could help dealerships, online markets, and analysts to quickly and accurately categorize cars by brand, as well as help predict what car brands commonly have which specs. On the other hand, if the model is biased or not trained on all the data properly, it might generate misleading classifications or oversimplify the complexity of different brands.
01Week 6 Prep: Classification
In this blog post we will discuss more classification algorithms.
2min
02Week 4 Prep: Classification & Decision Trees
In this blog post we will discuss a high level overview of some classification algorithms.
2min
03Week 11 Prep: Project 4 Intro
In this blog post, we will choose a problem to solve using clustering for Project 4.
2min